

-
摘要: 對注意力機制的主流模型進行了全面系統的概述。注意力機制模擬人類視覺選擇性的機制,其核心的目的是從冗雜的信息中選擇出對當前任務目標關聯性更大、更關鍵的信息而過濾噪聲,也就是高效率信息選擇和關注機制。首先簡要介紹和定義了注意力機制的原型,接著按照多個層面對各種注意力機制結構進行分類,然后對注意力機制的可解釋性進行了闡述同時總結了在各種領域的應用,最后指出了注意力機制未來的發展方向以及會面臨的挑戰。
-
關鍵詞:
- 注意力機制 /
- 全局/局部注意力機制 /
- 硬/軟注意力機制 /
- 自注意力機制 /
- 可解釋性
Abstract: There are two challenges with the traditional encoder–decoder framework. First, the encoder needs to compress all the necessary information of a source sentence into a fixed-length vector. Second, it is unable to model the alignment between the source and the target sentences, which is an essential aspect of structured output tasks, such as machine translation. To address these issues, the attention mechanism is introduced to the encoder–decoder model. This mechanism allows the model to align and translate by jointly learning a neural machine translation task. The whose core idea of this mechanism is to induce attention weights over the source sentences to prioritize the set of positions where relevant information is present for generating the next output token. Nowadays, this mechanism has become essential in neural networks, which have been researched for diverse applications. The present survey provides a systematic and comprehensive overview of the developments in attention modeling. The intuition behind attention modeling can be best explained by the simulation mechanism of human visual selectivity, which aims to select more relevant and critical information from tedious information for the current target task while ignoring other irrelevant information in a manner that assists in developing perception. In addition, attention mechanism is an efficient information selection and widely used in deep learning fields in recent years and played a pivotal role in natural language processing, speech recognition, and computer vision. This survey first briefly introduces the origin of the attention mechanism and defines a standard parametric and uniform model for encoder–decoder neural machine translation. Next, various techniques are grouped into coherent categories using types of alignment scores and number of sequences, abstraction levels, positions, and representations. A visual explanation of attention mechanism is then provided to a certain extent, and roles of attention mechanism in multiple application areas is summarized. Finally, this survey identified the future direction and challenges of the attention mechanism.-
Key words:
- attention mechanism /
- global/local attention /
- hard/soft attention /
- self-attention /
- interpretability
-
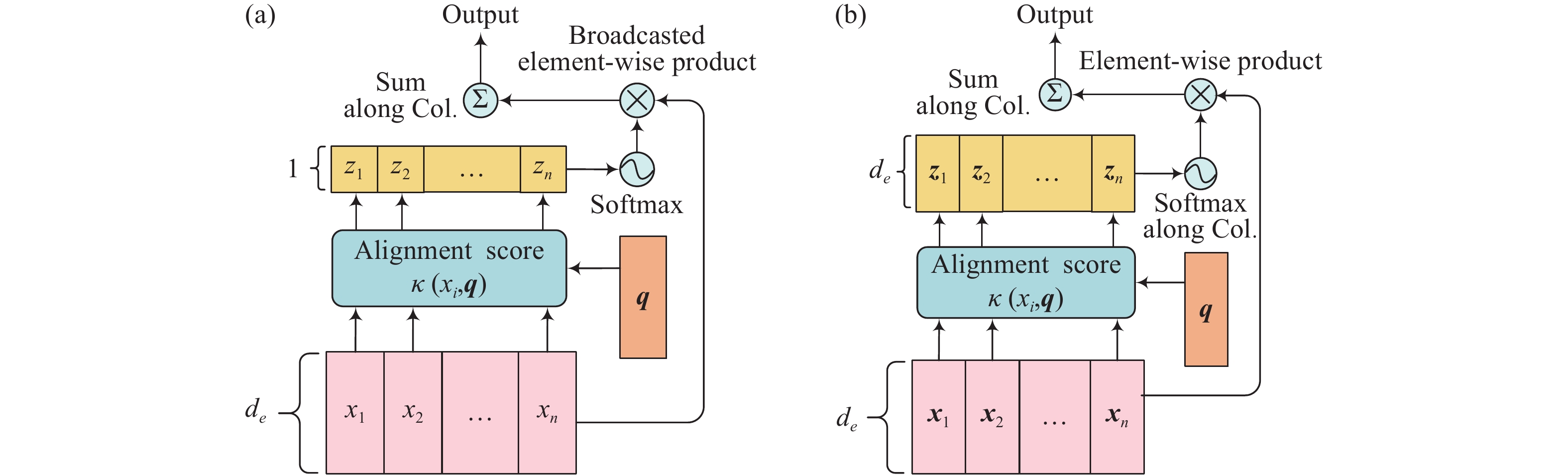
圖 3 經典注意力機制(a)和多維注意力機制(b) [11].
$ {z_i} \in \{ {z_1},{z_2},\cdots,{z_n}\} $ 為計算對齊函數$ \kappa ({x_i},{\boldsymbol{q}}) $ 得到的對應值,圖(a)中$ {z_i} $ 為標量,圖(b)中其值$ {z_i} $ 為向量Figure 3. Traditional (additive/multiplicative) attention (a) and multi-dimensional attention (b) [11].
${z_i}$ denotes the alignment score$ \kappa ({x_i},{\boldsymbol{q}}) $ , in figure (a)${z_i}$ is a scalar and in figure (b)$ {z_i} $ is a vector表 1 幾種常用的注意力機制及其對齊函數的數學形式
Table 1. Summary of several attention mechanisms and corresponding alignment score functions
Name of attention mechanism Alignment score functions References Content-base attention $ {\text{score(}}{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{h}}_t}{\text{)}} = {\text{cosine[}}{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{h}}_i}{\text{] }} $ [17] Additive attention $ {\text{score(}}{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{h}}_t}{\text{)}} = {\boldsymbol{v}}_a^{\text{T}}\tanh ({{\boldsymbol{W}}_a}{\text{[}}{{\boldsymbol{s}}_t};{{\boldsymbol{h}}_i}{\text{]}}) $ [3] Location-base attention $ \alpha _{t,i}^{} = {\text{softmax(}}{{\boldsymbol{W}}_a}{{\boldsymbol{s}}_t}{\text{)}} $ [6] Bi-linear attention $ {\text{score(}}{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{h}}_t}{\text{)}} = {\boldsymbol{s}}_t^{\text{T}}{{\boldsymbol{W}}_a}{{\boldsymbol{h}}_i} $ [6] Dot-product attention $ {\text{score(}}{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{h}}_t}{\text{)}} = {\boldsymbol{s}}_t^{\text{T}}{{\boldsymbol{h}}_i} $ [6] Scaled dot-product attention $ {\text{score(}}{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{h}}_t}{\text{)}} = {\boldsymbol{s}}_t^{\text{T}}{{\boldsymbol{h}}_i}{\text{/}}\sqrt n $ [10]  下載: 導出CSV
久色视频
下載: 導出CSV
久色视频表 2 重要的注意力機制模型從四個不同方面的總結
Table 2. Summary of key papers for technical approaches within each category
References Number of sequences Number of abstraction levels Number of representations Number of positions Scenario of applications [3] Distinctive Single-level Single-representational Soft Machine translation [5] Distinctive Single-level Single-representational Hard Image captioning [6] Distinctive Single-level Single-representational Local Machine translation [7] Self-attention Single-level Single-representational Soft Document classification [18] Distinctive Multi-level Single-representational Soft Speech recognition [21] Distinctive Single-level Single-representational Soft Visual question answering [22] Co-attention Multi-level Single-representational Soft Sentiment classification [23] Self-attention Multi-level Single-representational Soft Recommender systems [11] Self-attention Single-level Multi-representational Soft Language understanding [19] Self-attention Single-level Multi-representational Soft Text representation
下載: 導出CSV
-
參考文獻
[1] Carrasco M. Visual attention: The past 25 years. Vision Res, 2011, 51(13): 1484 doi: 10.1016/j.visres.2011.04.012 [2] Walther D, Rutishauser U, Koch C, et al. Selective visual attention enables learning and recognition of multiple objects in cluttered scenes. Comput Vis Image Underst, 2005, 100(1-2): 41 doi: 10.1016/j.cviu.2004.09.004 [3] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate // Proceedings of the 3rd International Conference on Learning Representations. San Diego, 2015: 1 [4] Cho K, van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [J/OL]. arXiv preprint (2014-6-3) [2020-12-16]. https://arxiv.org/abs/1406.1078 [5] Xu K, Ba J L, Kiros R, et al. Show, attend and tell: Neural image caption generation with visual attention // Proceedings of the 32nd International Conference on Machine Learning. Lille, 2015: 2048 [6] Luong T, Pham H, Manning C D. Effective approaches to Attention-based Neural Machine Translation // Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, 2015: 1412 [7] Yang Z C, Yang D Y, Dyer C, et al. Hierarchical Attention Networks for Document Classification // Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, 2016: 1480 [8] Zhang J M, Bargal S A, Lin Z, et al. Top-down neural attention by excitation backprop. Int J Comput Vis, 2018, 126(10): 1084 doi: 10.1007/s11263-017-1059-x [9] Gehring J, Auli M, Grangier D, et al. Convolutional sequence to sequence learning // Proceedings of the 34th International Conference on Machine Learning. Sydney, 2017: 1243 [10] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, 2017: 6000 [11] Shen T, Zhou T Y, Long G D, et al. DiSAN: directional self-attention network for RNN/CNN-free language understanding // Proceedings of the AAAI Conference on Artificial Intelligence. Louisiana, 2018: 32 [12] Lin Z H, Feng M W, Santos C N, et al. A structured self-attentive sentence embedding [J/OL]. arXiv preprint (2017-3-9) [2020-12-16].https://arxiv.org/abs/1703.03130 [13] Shen T, Zhou T Y, Long G D, et al. Bi-directional block self-attention for fast and memory-efficient sequence modeling // Proceedings of the 6th International Conference on Learning Representations. Vancouver, 2018: 1 [14] Shen T, Zhou T Y, Long G D, et al. Reinforced Self-Attention Network: a Hybrid of Hard and Soft Attention for Sequence Modeling // Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. Stockholm, 2018: 4345 [15] Kim Y, Denton C, Hoang L, et al. Structured attention networks [J/OL]. arXiv preprint (2017-2-16) [2020-12-16].https://arxiv.org/abs/1702.00887 [16] Chaudhari S, Mithal V, Polatkan G, et al. An attentive survey of attention models [J/OL]. arXiv preprint (2019-4-5) [2020-12-16]. https://arxiv.org/abs/1904.02874 [17] Mnih V, Heess N, Graves A. Recurrent models of visual attention // Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, 2014: 2204 [18] Chan W, Jaitly N, Le Q, et al. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition // 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Shanghai, 2016: 4960 [19] Kiela D, Wang C H, Cho K. Dynamic Meta-Embeddings for Improved Sentence Representations // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 1466 [20] Maharjan S, Montes M, González F A, et al. A genre-aware attention model to improve the likability prediction of books // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 3381 [21] Lu J S, Yang J W, Batra D, et al. Hierarchical question-image co-attention for visual question answering. Adv Neural Infor Processing Syst, 2016, 29: 289 [22] Wang W, Pan S J, Dahlmeier D, et al. Coupled multi-layer attentions for co-extraction of aspect and opinion terms // Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. San Francisco, 2017: 3316 [23] Ying H C, Zhuang F Z, Zhang F Z, et al. Sequential recommender system based on hierarchical attention networks // Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. Stockholm, 2018: 3926 [24] De-Arteaga M, Romanov A, Wallach H, et al. Bias in bios: a case study of semantic representation bias in a high-stakes setting // Proceedings of the Conference on Fairness, Accountability, and Transparency. Atlanta, 2019: 120 [25] Lee J, Shin J H, Kim J S. Interactive visualization and manipulation of attention-based neural machine translation // Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Copenhagen, 2017: 121 [26] Liu S S, Li T, Li Z M, et al. Visual Interrogation of Attention-Based Models for Natural Language Inference and Machine Comprehension // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Brussels, 2018: 36 [27] Jain S, Wallace B C. Attention is not explanation [J/OL]. arXiv preprint (2019-2-26) [2020-12-16].https://arxiv.org/abs/1902.10186 [28] Wiegreffe S, Pinter Y. Attention is not not explanation // Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, 2019: 11 [29] Jetley S, Lord N A, Lee N, et al. Learn to pay attention [J/OL]. arXiv preprint (2018-4-6) [2020-12-16].https://arxiv.org/abs/1804.02391 [30] Sharma S, Kiros R, Salakhutdinov R. Action recognition using visual attention [J/OL]. arXiv preprint (2015-12-12) [2020-12-16]. https://arxiv.org/abs/1511.04119 [31] Kataoka Y, Matsubara T, Uehara K. Image generation using generative adversarial networks and attention mechanism // 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS). Okayama, 2016: 1 [32] Gregor K, Danihelka I, Graves A, et al. Draw: A recurrent neural network for image generation // Proceedings of the 32nd International Conference on Machine Learning. Lille, 2015: 1462 [33] Parmar N, Vaswani A, Uszkoreit J, et al. Image transformer // Proceedings of the 35th International Conference on Machine Learning. Stockholm, 2018: 4052 [34] Huang P Y, Liu F, Shiang S R, et al. Attention-based Multimodal Neural Machine Translation // Proceedings of the First Conference on Machine Translation. Berlin, 2016: 639 [35] Zhang H, Goodfellow I, Metaxas D, et al. Self-attention generative adversarial networks // Proceedings of the 36nd International Conference on Machine Learning. Long Beach, 2019: 7354 [36] Cohn T, Hoang C D V, Vymolova E, et al. Incorporating structural alignment biases into an attentional neural translation model // Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, 2016: 876 [37] Feng S, Liu S, Yang N, et al. Improving attention modeling with implicit distortion and fertility for machine translation // Proceedings of the 26th International Conference on Computational Linguistic. Osaka, 2016: 3082 [38] Eriguchi A, Hashimoto K, Tsuruoka Y. Tree-to-sequence attentional neural machine translation // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, 2016: 823 [39] Sankaran B, Mi H, Al-Onaizan Y, et al. Temporal attention model for neural machine translation [J/OL]. arXiv preprint (2016-8-9) [2020-12-16].https://arxiv.org/abs/1608.02927 [40] Cheng Y, Shen S Q, He Z J, et al. Agreement-based joint training for bidirectional attention-based neural machine translation // Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. New York, 2016: 2761 [41] Liu L, Utiyama M, Finch A, et al. Neural machine translation with supervised attention [J/OL]. arXiv preprint (2016-9-14) [2020-12-16].https://arxiv.org/abs/1609.04186 [42] Britz D, Goldie A, Luong M T, et al. Massive exploration of neural machine translation architectures // Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, , 2017: 1442 [43] Tang G B, Müller M, Rios A, et al. Why Self-attention? A targeted evaluation of neural machine translation architectures // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 4263 [44] Yin W P, Schütze H, Xiang B, et al. ABCNN: attention-based convolutional neural network for modeling sentence pairs. Trans Assoc Comput Linguist, 2016, 4: 259 doi: 10.1162/tacl_a_00097 [45] Zhuang P Q, Wang Y L, Qiao Y. Learning attentive pairwise interaction for fine-grained classification. Proc AAAI Conf Artif Intell, 2020, 34(7): 13130 [46] Zhou P, Shi W, Tian J, et al. Attention-based bidirectional long short-term memory networks for relation classification // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, 2016: 207 [47] Wang Y Q, Huang M L, zhu X Y, et al. Attention-based LSTM for aspect-level sentiment classification // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, 2016: 606 [48] Ma Y, Peng H, Cambria E. Targeted aspect-based sentiment analysis via embedding commonsense knowledge into an attentive LSTM // Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. New Orleans, 2018: 5876 [49] Zhang S C, Loweimi E, Bell P, et al. On the usefulness of self-attention for automatic speech recognition with transformers // Proceedings of 2021 IEEE Spoken Language Technology Workshop (SLT). Shenzhen, 2021: 89 [50] Sar? L, Moritz N, Hori T, et al. Unsupervised speaker adaptation using attention-based speaker memory for end-to-end ASR // Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Barcelona, 2020: 7384 [51] Chorowski J, Bahdanau D, Serdyuk D, et al. An online attention-based model for speech recognition [J/OL]. arXiv preprint (2015-06-24) [2020-12-16].https://arxiv.org/abs/1506.07503 [52] Bahdanau D, Chorowski J, Serdyuk D, et al. End-to-end attention-based large vocabulary speech recognition // Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Shanghai, 2016: 4945 [53] Shen S, Lee H. Neural attention models for sequence classification: Analysis and application to key term extraction and dialogue act detection [J/OL]. arXiv preprint (2016-3-31) [2020-12-16].https://arxiv.org/abs/1604.00077 [54] Liu B, Lane I. Attention-based recurrent neural network models for joint intent detection and slot filling [J/OL]. arXiv preprint (2016-9-6) [2020-12-16].https://arxiv.org/abs/1609.01454 [55] Shen Y, Tan S, Sordoni A, et al. Ordered neurons: Integrating tree structures into recurrent neural networks [J/OL]. arXiv preprint (2018-10-22) [2020-12-16].https://arxiv.org/abs/1810.09536 [56] Nguyen X P, Joty S, Hoi S C H, et al. Tree-structured attention with hierarchical accumulation [J/OL]. arXiv preprint (2020-2-19) [2020-12-16].https://arxiv.org/abs/2002.08046 [57] Tsai Y H H, Srivastava N, Goh H, et al. Capsules with inverted dot-product attention routing [J/OL]. arXiv preprint (2020-2-19) [2020-12-16].https://arxiv.org/abs/2002.04764 -









 點擊查看大圖
點擊查看大圖
計量
- 文章訪問數: 1842
- HTML全文瀏覽量: 611
- PDF下載量: 379
- 被引次數: 0
